En la era de las redes sociales, la música se ha convertido en una forma de entretenimiento cada vez más importante para las personas de todo el mundo. Con el surgimiento de plataformas de “transmisión por demanda” (streaming) como Spotify, los oyentes pueden acceder a millones de canciones al instante y sin tocar productos físicos, evitando también las descargas ilegales que han sido un dolor de cabeza durante años para la industria.
Sin embargo, con tanta música disponible, la pregunta es: ¿cómo se asegura Spotify de que los usuarios encuentren lo que están buscando? ¿cómo se les presenta música que potencialmente les pueda gustar? La respuesta es simple: a través del uso de modelos matemáticos que funcionan como algoritmos de predicción.
Esta información sumada con mi experiencia obteniendo millones de reproducciones, me sirvió para desarrollar un Curso de Spotify para Artistas Musicales y una Masterclass sobre el Algoritmo de Spotify (con explicaciones aún más profundas sobre playlists y estrategias para artistas).
En este artículo, te voy a contar cómo funciona el algoritmo de Spotify, como nadie lo ha hecho antes y con ejemplos básicos para que esto sea totalmente comprensible, desde artistas independientes hasta expertos o simplemente oyentes, repasando los métodos que la propia compañía ha declarado usar y algunos otros que están a nuestro alcance.

¿Qué es un algoritmo?
En términos simples, un algoritmo es una serie de instrucciones que, en este caso, una computadora sigue para realizar una tarea específica, similar a una receta de cocina o un manual de instrucciones. Se utilizan en una variedad de aplicaciones, desde motores de búsqueda hasta redes sociales y son esenciales para que estas aplicaciones funcionen de manera eficiente, siendo en este caso el sistema de recomendación que permite ofrecer canciones similares basadas en los gustos y actividades del usuario.

La plataforma en el front-end
Aquí los algoritmos analizan los hábitos de escucha de los usuarios para proporcionar recomendaciones personalizadas a través de modelos matemáticos de predicción. Su función se basa en tres factores principales:
- Perfil e historial de usuario: Se analizan las canciones que el usuario ha escuchado y se comparan con el catálogo de millones de canciones. Esto permite que el algoritmo haga recomendaciones basadas en las preferencias musicales del usuario, asumiendo que podrían gustarle canciones similares.
- Hábitos de escucha de usuarios similares: Se analizan los hábitos de escucha de otros usuarios en múltiples e infinitas matrices, cruzando información con aquellos que escuchan canciones similares, les han dado like o las han guardado en listas de reproducción personales. Esto permite que el algoritmo haga recomendaciones de nuevas canciones y artistas que probablemente sean de interés para el usuario, cruzando información entre ellos.
- Popularidad de las canciones: Spotify también tiene en cuenta la popularidad de una canción o artista, especialmente aquellos que se destacan en listas de reproducción editoriales. Si una canción es popular entre muchos usuarios, es más probable que el algoritmo de recomendación la sugiera a otros usuarios con gustos similares. Esto ocurre mediante una combinación de algoritmos de procesamiento y datos obtenidos previamente.
Además de proporcionar recomendaciones personalizadas, el algoritmo de Spotify también se utiliza para crear listas de reproducción curadas. Por ejemplo, Descubrimiento semanal se actualiza cada lunes y es una playlist diseñada para presentar a los usuarios nuevas canciones y artistas que es probable que les gusten. Incluye no solo canciones de artistas populares, sino también pistas de todo el catálogo de nuevos lanzamientos.


¿Cómo crearon el algoritmo?
Fue un proceso largo y complejo que involucró a muchos expertos en el campo de la ciencia de datos e inteligencia artificial. El algoritmo ha sido continuamente mejorado a lo largo de los años y Spotify sigue invirtiendo enormes recursos en el desarrollo de tecnologías de recomendación cada vez más sofisticadas, ofreciendo una experiencia de hiper-personalización en la que cada usuario percibe la música según su personalidad.
Véase también Personalidad de los oyentes según Spotify.

La compañía se dio cuenta de cómo aprovechar el cambio de paradigma en el que la piratería, particularmente The Pirate Bay, comenzó a ser mal vista y se podían hacer acuerdos innovadores con sellos discográficos para ofrecer música en línea. Esto llevó a las primeras versiones de Spotify a centrarse en atraer a personas interesadas en acceder a vastos catálogos de música de alta calidad sin lidiar con descargas sospechosas de P2P. Después de los primeros años de éxito, Spotify comenzó a verse a sí misma no solo como una aplicación de escucha de música, sino como una plataforma social de gestión de música que se convirtió en parte de la vida diaria de los usuarios. Y ciertamente han logrado eso.
Este objetivo ambicioso ha requerido extensos estudios psicológicos y sociológicos para comprender el comportamiento humano con respecto a sus hábitos de escucha e intereses en artistas específicos en determinados momentos del día. Rápidamente se dieron cuenta de que la “cultura del algoritmo” estaba a punto de posicionarse como mediador entre la experiencia del usuario y plataformas líderes como Facebook.
The Echo Nest, una empresa que había acumulado datos sobre 30 millones de canciones utilizando inteligencia artificial para el año 2014, fue adquirida por Spotify para mejorar la experiencia del usuario con recomendaciones personalizadas. Aquí es donde se produce el cambio importante, con la incorporación de inteligencia artificial capaz de proporcionar información detallada sobre cada canción catalogada a través de su API.
Esto nos hace dar cuenta de la importancia de los metadatos cuando enviamos nuestra música para su distribución, ya que la falta de información puede hacer que nuestras canciones sean menos relevantes para el algoritmo y simplemente reciban menos recomendaciones o ninguna en absoluto.
Para crear y actualizar el algoritmo de Spotify, el equipo de la plataforma tuvo que recopilar una inmensa cantidad de datos sobre los hábitos de escucha de los usuarios. Estos datos incluyen información muy específica sobre las canciones más escuchadas con mayor frecuencia, las canciones que se omiten con más frecuencia y las canciones guardadas en las listas de reproducción generadas por los usuarios.
El equipo de Spotify utilizó técnicas de aprendizaje automático y análisis de datos para crear modelos que pudieran predecir qué canciones y artistas le gustarían a un usuario en función de sus hábitos de escucha. Estos modelos también tuvieron en cuenta la popularidad de las canciones y artistas, así como otros factores como la duración de la canción y el género, que lo veremos luego.
A medida que el algoritmo de Spotify se ha desarrollado y mejorado, el equipo de la plataforma ha implementado técnicas más avanzadas, como el uso de redes neuronales y el análisis de datos de comportamiento en tiempo real. Esto ha hecho que la integración de datos entre diferentes algoritmos sea cada vez más precisa en la recomendación de música a los usuarios, planteando una pregunta importante: ¿hasta qué punto es efectiva la recomendación?
¿Qué es un filtro?
En 2006, Netflix ofreció un premio a cualquiera que pudiera proporcionar el mejor cálculo de predicción para películas. Basado en el comportamiento del usuario, el objetivo era hacer la mejor recomendación posible. El premio de 1 millón de dólares se otorgó en 2009 y desde entonces hemos aprendido mucho más sobre el filtrado colaborativo, especialmente sobre Cinematch, el algoritmo de Netflix, parte del código que se emplearía también en Spotify.
Pero empecemos por lo básico… ¿Qué es un filtro? Es un algoritmo utilizado para la recopilación de datos. Un filtro de contenido seleccionará una parte de la matriz analizada. Por ejemplo, la siguiente tabla consta de X usuarios e Y canciones, mientras que los números contienen un rango del 0 al 2 para representar la probabilidad:
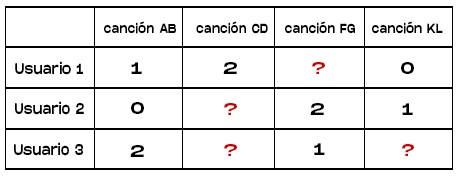
Los números aquí podrían representar la calificación que el usuario ha dado a la canción, donde 0 significaría “no me gusta”, 1 significaría “neutral” y 2 significaría “me gusta”. Los valores faltantes representados por signos de interrogación son aquellos que deberíamos tratar de predecir utilizando los modelos matemáticos.
Filtro de contenido
En este ejemplo, utilizaremos información proporcionada por el usuario como el tejido conectivo para la predicción. Comenzaremos agregando características para cada usuario y canción, con un rango de valores de 0 a 3:
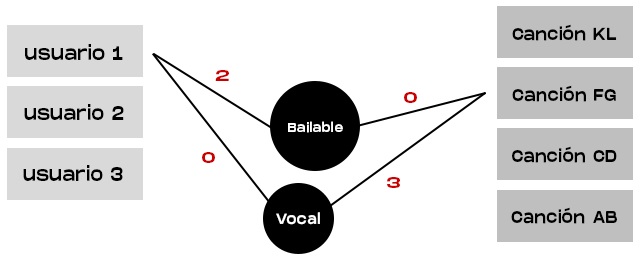
El usuario 1 probablemente disfrute de canciones bailables pero rechace en su mayoría las canciones vocales, por lo que habrá dos características: “bailable” con un valor de 2 y “vocal” con un valor de 0. Ahora, la canción FG no es bailable pero tiene una fuerte presencia vocal, por lo que “bailable” tendrá un valor de 0 y “vocal” tendrá un valor de 3.
Si queremos predecir si al usuario 1 le gustará la canción FG, necesitamos multiplicar estos factores para representar la posible conexión entre el usuario 1 y la canción FG de la siguiente manera:
(2 * 0) + (0 * 3) = 0
Nuestra predicción es que al usuario 1 no le gustará la canción FG.
Para realizar predicciones cada vez más precisas (o al menos intentarlo), se creará un registro de todas las preferencias de los usuarios y las características de las canciones, lo que permitirá realizar tantas factorizaciones como sean necesarias para determinar posibles recomendaciones para cada usuario en las canciones faltantes.
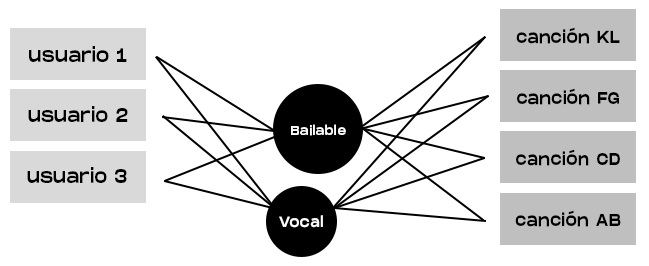
Pasemos a una instancia de dos matrices donde podemos recopilar toda la información de usuarios y canciones:
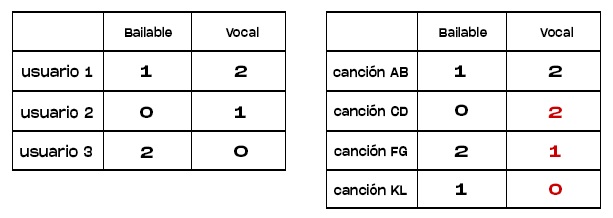
Una matriz contiene la asignación entre usuarios y características, mientras que la otra matriz contiene la asignación entre canciones y características. Si calculamos los datos entre estas dos matrices empleando la factorización antes vista, obtendremos resultados de predicción potencialmente más precisos.

Este ejemplo sirve para mostrar cómo los datos pueden ser cruzados matemáticamente, pero aún parece bastante básico. Volviendo al caso de Netflix, en sus primeros años realizaron una encuesta bastante extensa para recopilar datos y preferencias de los usuarios con el fin de proporcionar recomendaciones basadas en esa información. Sin embargo, sabemos que las preferencias de los usuarios pueden cambiar con el tiempo, o simplemente pueden consumir contenido fuera de sus preferencias habituales por diversas razones y les gustaría recibir recomendaciones similares.
Filtro colaborativo
Para lograr esto, la solución fue el filtrado colaborativo, que cruza la información de actividad del usuario con la de otros usuarios para encontrar similitudes en recomendaciones potenciales. En el caso de Spotify, se recopila el historial de canciones que diferentes usuarios han gustado o al menos escuchado en su totalidad (ya que las canciones omitidas también forman parte de los datos a filtrar).
Para explicarlo de manera sencilla, observemos el siguiente diagrama de Venn:
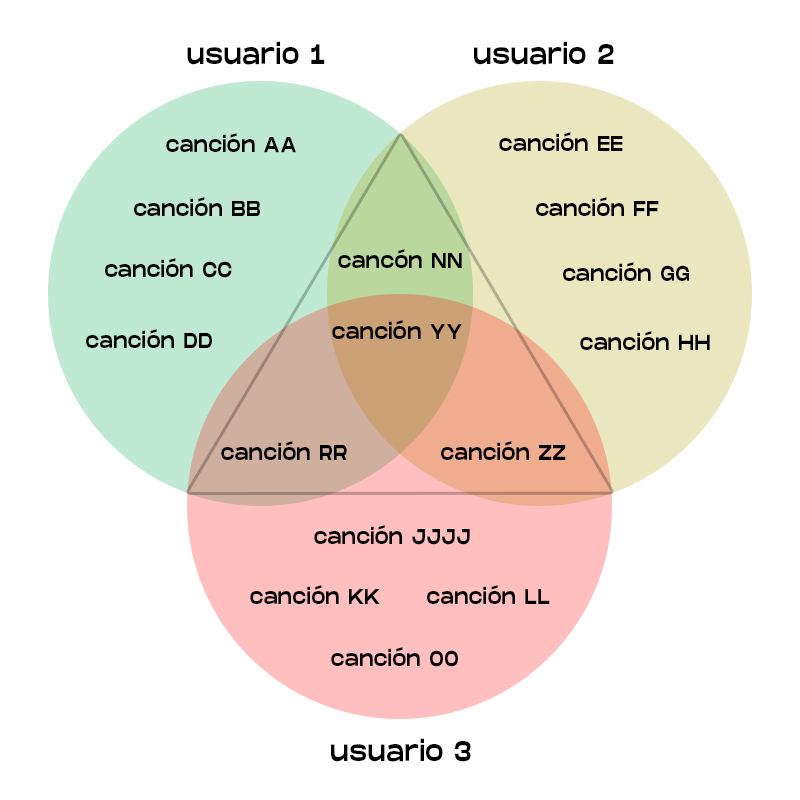
Como se puede ver en las áreas de intersección, la canción YY es escogida por los tres usuarios, mientras que diferentes pares de usuarios gustan de la canción NN, la canción RR y la canción ZZ. La probabilidad de recomendación entonces se encuentra entre estas tres canciones, que serán potencialmente recomendadas al usuario restante en cada intersección de dos usuarios, y la canción YY puede ser fácilmente recomendada a otros usuarios con gustos similares.
Imaginemos diagramas de Venn que tienden al infinito en tanto se entrecruzan los datos de los usuarios para cada actividad.

Es importante tener en cuenta que el algoritmo de filtrado colaborativo de Spotify se basa en datos históricos y comentarios de los usuarios. Por lo tanto, cuanto más interactúa un usuario con la plataforma, mejor será la calidad de las recomendaciones que recibe. A medida que los usuarios escuchan más canciones y crean más listas de reproducción, el algoritmo de Spotify tiene más datos con los que trabajar y puede hacer recomendaciones más precisas. Sí, definitivamente se vuelve infinito.
Procesamiento de Lenguaje Natural (PLN)
Este es un concepto utilizado en inteligencia artificial para agrupar métodos de comunicación que son universales en la recopilación y entrega de información. Spotify analiza cómo se utiliza el lenguaje natural en varios blogs, sitios web y foros de discusión cuando se habla de artistas, canciones, álbumes para determinar qué se está diciendo sobre ellos. Esto implica agrupar diferentes términos como adjetivos, sustantivos y también oraciones o frases completas (que al final son el núcleo del procesamiento de lenguaje natural). A cada término analizado se le asigna una puntuación basada en el “peso” de la oración o componente lingüístico encontrado en la web. Similar a lo que el algoritmo Page Rank de Google también hace en la actualidad.
Un modelo avanzado de PLN también captura el estilo de las letras para entender de qué está hablando el artista y quién es su público objetivo. Se tienen en cuenta las listas de reproducción a las que se agregan canciones, así como sus títulos y descripciones, para asociar canciones y artistas con comportamientos, géneros y estados de ánimo específicos.
Los modelos de procesamiento del lenguaje operan con los siguientes principios:
- Morfología: Se ocupa de la construcción de palabras a partir de unidades más pequeñas que tienen significado.
- Sintaxis: Se enfoca en cómo se organizan las palabras para formar oraciones gramaticalmente correctas y el papel que cada palabra desempeña en la estructura de la oración.
- Semántica: Explora el significado de las palabras y cómo estos significados se combinan para transmitir el significado de una frase en particular.
- Pragmática: Examina cómo se usan las oraciones en diferentes contextos y cómo su uso influye en la interpretación de la oración.
- Discurso: Considera cómo las oraciones anteriores afectan la comprensión e interpretación de la siguiente oración.
Si hay varios blogs que hablan positivamente de tu lanzamiento, el filtro primero verificará que no haya un copy/paste (o sea, trampa), sino una repartición adecuada de cierta información (metadatos). Luego, las opiniones se separarán, distinguiendo entre negativas y positivas, para evaluar la popularidad de tu lanzamiento.
Análisis del audio
Aquí es donde se vuelve realmente interesante. Spotify tiene la capacidad de analizar cada archivo de audio asociado a una canción utilizando redes neuronales convolucionales (CNN, por sus siglas en inglés). Ahora se pueden asociar características específicas a cada material de audio, lo que permite agrupar canciones y cruzar esta información con los filtros colaborativos. Esto se logra cortando cada material de audio en pequeñas piezas y midiendo la información del audio con una base de datos para agrupar las canciones con la información específica con la que trabajar.
Aquí está la información y sus rangos de puntuación:
- Key: 0 a 11; desconocido = -1
- Mode: 0 (menor) a 1.00 (mayor)
- Acousticness: 0 a 1.00
- Danceability: 0 a 1.00
- Energy: 0 a 1.00
- Instrumentalness: 0 a 1.00
- Loudness: -60dB a 0dB
- Valence: 0 a 1.00 (positividad)
- Liveness: 0 a 1.00
- Tempo: 0 a infinito BPM
- Popularity: 0 a 100
Correlación
Es una medida estadística utilizada para evaluar la relación entre dos variables. En el contexto de Spotify, se puede utilizar para analizar la relación entre diferentes características de las canciones analizadas mediante el modelado de audio y determinar si existe una asociación entre ellas. La correlación se representa mediante un coeficiente que varía de -1 a 1. Un valor de -1 indica una correlación negativa perfecta, 0 indica ninguna correlación y 1 indica una correlación positiva perfecta.
Supongamos que tenemos un conjunto de datos de 100 canciones y queremos determinar si existe una correlación entre la valencia (la medida de positividad o negatividad) y la popularidad de las canciones. Asignamos valores numéricos a la valencia y popularidad de cada canción y calculamos el coeficiente de correlación.
Valencia (X): [0.3, 0.4, 0.2, 0.8, 0.5, 0.4, 0.9, 0.5, 0.6, 0.2, 0.3, 0.5, …]
Popularidad(Y): [70, 85, 60, 55, 90, 80, 65, 75, 85, 70, 50, 95, …]
Aplicamos la fórmula para el coeficiente de correlación (por ejemplo, el coeficiente de correlación de Pearson) y obtenemos un valor, por ejemplo, 0.7. Esto indica una correlación positiva moderada entre la valencia y la popularidad de las canciones, lo que significa que las canciones con una valencia más alta tienden a ser más populares.
Utilizando estos coeficientes, se pueden analizar numerosas correlaciones entre variables que te permitirán organizar mejor la información sobre cómo funciona Spotify.
Similitud del coseno
Un enfoque para entender el procesamiento del lenguaje natural se puede realizar con este modelo matemático. Supongamos que hay 4 blogs que discuten una canción y queremos determinar si mayormente tienen opiniones positivas o negativas, identificando algunas frases similares:
Blog 1: “Es una canción muy enérgica y buena.”
Blog 2: “Es bailable, muy enérgica.”
Blog 3: “No es tan bailable.”
Blog 4: “Es extremadamente enérgica y poderosa.”
A primera vista, se puede reconocer que el tercer blog no tuvo una visión positiva sobre la canción. Ahora, imagina que la información que recibes proviene de 500 blogs y necesitas obtener el resultado más preciso en el análisis en un corto período de tiempo. Aquí es donde imaginamos una posible solución.
La similitud del coseno puede proporcionar un resultado que indica cuán similares o diferentes son las cosas…
Trabajemos con el ejemplo más básico:
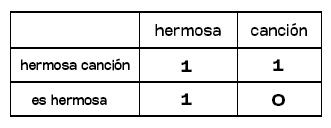
“Hermosa canción.”
“Es hermosa.”
Queremos saber qué tan similares son estas dos oraciones. Crearemos una tabla donde colocaremos las palabras que nos interesan:
Con estos datos vamos a crear este gráfico:

En el eje X tendremos la palabra “hermosa”, y en el eje Y tendremos la palabra “canción”. Dado que la primera oración contiene ambas palabras, se intersectarán en (1, 1). La segunda oración solo contiene la palabra “hermosa”, por lo que se intersectará en (1, 0). El ángulo formado por estos dos puntos es de 45 grados, y el coseno de 45 grados es 0.71. La similitud para estas dos oraciones es 0.71. Si la palabra “hermosa” hubiese aparecido más veces en la segunda oración, el resultado habría sido el mismo.
Ahora veamos estos dos ejemplos:
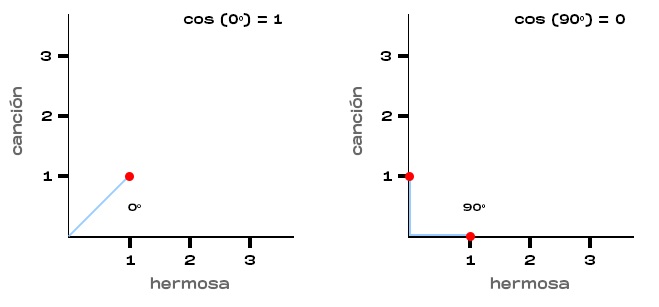
Si ambas oraciones hubieran dicho “hermosa canción”, su similitud se habría expresado como 1, resultado de calcular el coseno de 0 grados. Si una oración contiene solo la palabra “hermosa” y la otra contiene la palabra “canción”, no tendrían similitud ya que el coseno de 90 grados es igual a 0.
Afortunadamente, existe una fórmula que simplifica todos estos pasos y nos permite relacionar más palabras juntas (creando más dimensiones imposibles de graficar).
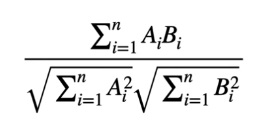
Aquellos que hayan estudiado estadística probablemente hayan visto cómo utilizarla. Y así es como podríamos estar utilizando fórmulas para comparar más de 2 oraciones y hacer predicciones.
Importante destacar
Los modelos matemáticos utilizados por Spotify en la actualidad no son específicamente los presentados en este artículo, sino modelos mucho más complejos desconocidos por motivos de propiedad intelectual y secreto corporativo. Tanto la empresa como científicos e investigadores privados han proporcionado suficiente información para concluir que estos modelos han evolucionado desde 2006 hasta el presente, con la incorporación de tecnologías de aprendizaje profundo, redes neuronales e inteligencia artificial.
Si sos experto en matemáticas y estadística, podrías construir tus propios modelos matemáticos para obtener resultados mucho más detallados para tus predicciones musicales en campañas de marketing musical, analizando conjuntos de datos de cientos de miles de canciones o cualquier información que desees comparar para generar predicciones sobre la popularidad, valencia o incluso análisis de ubicación en listas de reproducción.
Comportamiento del usuario
El algoritmo captura constantemente los patrones de comportamiento de cada usuario, no solo sus gustos preferenciales. Hay dos tipos de retroalimentación del usuario:
- Explícita: guardar, dar me gusta, agregar a listas de reproducción, compartir, saltar, seguir, descargar.
- Implícita: duración de la sesión, historial, reproducciones repetidas.
Diferentes modelos matemáticos pueden deducir el tipo de comportamiento exhibido por cada usuario en comparación con sus preferencias, según los siguientes resultados:
- Canciones favoritas
- Artistas favoritos
- Género
- Estado de ánimo
- Estilo
- Preferencias de era
- Popularidad
- Diversidad
- Datos demográficos
- Geolocalización de la sesión
¿Ahora entendés por qué Spotify te envía un resumen anual de tu actividad? Han estado rastreando todo. De hecho, te conocen más que vos mismo.
Características básicas
Como usuario de Spotify, ya sea freemium o premium, existen cuatro elementos principales cuando se trata de descubrir nueva música:
- A los fans también les gusta: Enumera artistas que se consideran similares al que estás escuchando.
- Descubrimiento semanal: Sugiere música personalizada basada en escuchas anteriores y lo que Spotify considera similar a esas escuchas.
- Radar de novedades: Busca canciones recién lanzadas que podrían ser de tu interés.
- Buscar: Recopila las características más importantes de Spotify, incluyendo las dos mencionadas anteriormente.
Comportamiento del algoritmo
En un estudio de investigación con múltiples casos (Eriksson et al., 2016) que utilizó bots para examinar el comportamiento del algoritmo al recomendar música, uno de los experimentos involucró a 32 bots diferenciados únicamente por edad en cuatro segmentos de edad: 93 años, 63 años, 33 años y 13 años. Se les presentaron 10 canciones seleccionadas de las siguientes listas: Billboard Hot Country, Billboard Hot Latin, Kids y Spotify Rewind (canciones de los años 60 y 70). Para dos bots en cada rango de edad, se proporcionó la misma música. La información recopilada de las “Principales recomendaciones para ti” se recopiló durante un período de 6 semanas, enfocándose solo en los artistas y no en sus álbumes.
Los resultados arrojaron 21.000 recomendaciones para un total de 1.809 artistas. En otras palabras, se recomendaron repetidamente un gran número de artistas, lo que representó aproximadamente el 70% de las recomendaciones. El porcentaje de música específica para cada grupo de edad fue sorprendentemente bajo (0.3% a 2% del total de recomendaciones). El grupo de dos bots de 93 años, que “escucharon” Spotify Rewind, recibió la mayor proporción de recomendaciones específicas para su edad (6%).
Las parejas de grupos de edad más altos (93 y 63 años) recibieron una mayor variedad de recomendaciones de artistas en términos de diversidad.
Uno de los ocho bots del grupo de Kids (de 63 años) recibió recomendaciones de 127 artistas diferentes, mientras que los otros siete bots no recibieron ninguna. Esto fue inusual. Entre los artistas recomendados se encontraban Beyoncé, Katy Perry, Zara Larsson, Bon Jovi y Christina Aguilera, que se presume que se recomiendan principalmente para el grupo de edad de 33 años.
Quizás esta información nos pueda ayudar a descartar elementos que parecen ser priorizados al recibir recomendaciones algorítmicas de Spotify, entendiendo que existen numerosos elementos e información que se consideran para determinar lo que potencialmente “nos gusta” escuchar.
Recomendaciones de playlists
Otra garantía que ofrece Spotify para la experiencia del usuario es la recomendación de listas de reproducción completas, no solo canciones individuales. Las listas de reproducción destacadas mapean y brindan contexto musical, tanto en términos de crear un aura afectiva alrededor de los sonidos como de aproximar los comportamientos y preferencias de los oyentes (Eriksson et al., 2017).
En el estudio de caso que voy a ejemplificar ahora, se tuvieron en cuenta tres conceptos esenciales: temporalidad, funcionalidad e intimidad, reconociendo la existencia (aún) del libre albedrío, lo que significa que cuando se presentan listas de reproducción destacadas, los usuarios pueden optar por ignorarlas y explorar otros ámbitos musicales.
Se crearon tres cuentas diferentes para recopilar la información presentada a cada cuenta en función del comportamiento del usuario. Estas cuentas representaban perfiles femeninos de 25 años de Suecia, Estados Unidos y Argentina. Durante una semana, cada perfil inició sesión en Spotify cada hora utilizando un script automatizado.
Entre la información recopilada al final del experimento, el primer resultado fue que el perfil argentino recibió 117 recomendaciones de listas de reproducción, mientras que los perfiles sueco y estadounidense recibieron 212 y 213 respectivamente, totalizando 542 recomendaciones. A lo largo del experimento, se informó que el 91% de las listas de reproducción eran repetitivas.
Ahora, lleguemos a la parte interesante. Un saludo de Spotify es un mensaje de bienvenida personalizado que la plataforma entrega a todos los usuarios al iniciar sesión. Teniendo en cuenta el primer concepto, temporalidad, era bastante obvio recibir mensajes como “¡Bienvenido a una nueva semana!” los lunes por la mañana, mientras que los martes decía “Despiértate con buenas vibraciones”. Las listas de reproducción que acompañaban estos mensajes se llamaban “Sunny side up” (¿podrían estar relacionadas con el pronóstico del tiempo?) y “Songs to sing in the shower”, entre otras. Muchas de las otras listas de reproducción contenían mensajes relacionados con el trabajo, con imágenes de portada que mostraban interiores similares a una oficina, aludiendo a un estilo de vida laboral capitalista occidental tal como es percibido por el usuario.
Por la tarde, aparecía un saludo ligeramente más atento, como “Un empujón de energía por la tarde…” acompañado de listas de reproducción como “Mantén la calma y concéntrate” o “Trabajo, trabajo, trabajo” en contraste con listas de reproducción más animadas como “Adrenalina” y “Ejercicio intenso”. ¿Cree Spotify que todos llevan ese tipo de vida?
La hiper-personalización
Después de las 4 pm, Spotify asume que estamos de vuelta en casa. “Relax y desconexión” o “Camino largo a casa” establecen el ambiente. Afortunadamente, el enfoque cambia hacia el fin de semana. Los viernes por la noche, los tres perfiles recibieron mensajes como “¡Que empiece el fin de semana!” o “Siente la fiebre del viernes”. Por la noche, Spotify anticipa que los usuarios estarán en casa tranquilamente, y aparecen con frecuencia listas de reproducción como “Tiempo acogedor en casa”. Y finalmente, “Sleepify” para ir a dormir.
En términos de funcionalidad, leer los saludos de Spotify o las descripciones de las listas de reproducción como “Conquista tu mañana”, “Como un jefe” o “Estás en la cima del mundo” añade importancia al hecho de que la plataforma coloca al usuario en una posición de alta valoración, conectada a la productividad y eficiencia laboral. Spotify realmente desea que la música sea el medio a través del cual la vida simplemente sucede, y esto no puede ser criticado negativamente, ya que a menudo asumimos que la música acompaña momentos importantes de nuestros días y los recuerdos asociados a ellos.
Por último, el concepto de intimidad. Al dirigirse imperativamente al usuario, Spotify pretende hacer que se sienta conectado a la plataforma. En su mente, el usuario se convierte en parte de la empresa a través de la experiencia. Un saludo de Spotify como “¿Problemas para dormir?” sugiere un escenario particular, un momento muy personal para cualquier persona, y ahí es donde se busca la monetización. El lenguaje utilizado para cada momento del día también es notable, con una retórica estratégicamente diseñada para generar sensaciones amigables entre el usuario y la plataforma.
Entonces, Spotify confía en que abramos nuestros corazones y presionemos el botón de reproducción en las canciones recomendadas para momentos específicos del día que la plataforma asume. Es posible que estés de vacaciones, explorando la ciudad de Nueva York, y aunque la plataforma sabe dónde estás, aún puede asumir que estás en una oficina trabajando. Sin embargo, la reacción psicológica en términos de nuestra “necesidad de pertenecer” sería que queremos escuchar las ofertas musicales solo si realmente estamos experimentando ese momento específico literalmente, por ejemplo, al regresar a casa después de un largo día de trabajo.
¿Qué saben ellos de nuestras emociones?
En 2018, Spotify presentó una patente detallando sus intenciones de recopilar información basada en la “experiencia emocional” del usuario, incluyendo datos como género, ubicación, estado civil, horarios laborales e incluso acento, entre otros. Esto permitiría, incluyendo el análisis de la voz utilizando inteligencia artificial, determinar la hora del día del usuario, posibles conexiones sociales y objetivos específicos en cualquier momento dado, con el fin de comprender el estado mental y emocional del usuario mientras trabaja, si está solo, si estudia o pasa tiempo con amigos, incluyendo toneladas de otros escenarios a predecir. Los datos de esta patente indican que la entrada de audio inicialmente separa la voz principal del ruido de fondo para procesarlos a través de sendos canales.

En primer lugar, el audio principal se analizará, separándolo en diferentes “discursos” mediante análisis de frecuencia (análisis de audio como en las canciones). Además, se analizará el audio de fondo para recopilar información ambiental, como ruidos de la calle, sonidos de impresora, personas hablando, etc., con el fin de predecir lo que el usuario está haciendo. Mediante el uso de un árbol de sintaxis, se pueden detectar énfasis y energía en ciertas palabras, indicando un orden de interés.
¿De qué otra manera Spotify registra mi actividad?
En 2016 se reveló que Spotify había creado artistas ficticios para poblar sus listas de reproducción basadas en el estado de ánimo. Además, una parte significativa de las listas de reproducción que se nos presentan en función de nuestro comportamiento son creadas por Filtr, Topsify y Digster, compañías propiedad de Sony, Warner y Universal, respectivamente. Esta información nos lleva al siguiente análisis: las tres compañías que dominan la industria a nivel mundial también están involucradas en los sesgos a través de los cuales Spotify pretende conocernos, o más bien manipularnos para escuchar lo que ellos quieren, dirigiéndonos o intentando dirigirnos a sus listas de reproducción “prefabricadas”.
Sí, probablemente te estés preguntando si Facebook y Google actúan de la misma manera.. Creo que ya conocés la respuesta.
¿Cómo puedo saber qué información tienen sobre mi actividad?
Bueno, esto es simple. En la versión web, deberás ir a Configuración de privacidad > Administrar tus datos > Descargar tus datos. Se te presentarán tres conjuntos de información para elegir, y después de un tiempo, lo recibirás por correo electrónico. Por supuesto, esta no es toda la información a la que nos referimos en relación con estos algoritmos. Te permitirá ver qué actividad registra la aplicación cuando la usas y qué información puede venderse a otras plataformas. De esta manera, puedes tomar una decisión informada sobre restringir la vinculación entre aplicaciones si deseas dificultar la vigilancia en tu cuenta.
¿Cómo aprovechan los artistas toda esta información?
Para los artistas, el algoritmo de Spotify puede ser una herramienta valiosa para promocionar su música y mejorar su posición en la plataforma. Diseñemos una estrategia integral que abarque todos los aspectos que ofrece la plataforma.
Comencemos con el aspecto social:
- Tener presencia en la plataforma: Para que el algoritmo de Spotify recomiende tu música a los usuarios, es importante tener un perfil de artista completo y actualizado que coincida con la información que se encuentra en la web (como biografías de SoundCloud o Beatport, por ejemplo). El procesamiento del lenguaje natural necesita verificar que tu identidad no contenga información que interfiera con tu historia como artista.
- Generar interacción: El algoritmo de Spotify también tiene en cuenta la interacción de los usuarios con canciones y artistas. Es importante fomentar la interacción con tus fanáticos en la plataforma. Esto puede incluir compartir listas de reproducción seleccionadas, publicar actualizaciones y responder a los comentarios de los fanáticos. Siempre es una prioridad para el artista motivar a los usuarios a escuchar su música tanto como sea posible y a interactuar con ella a través de likes y saves, asegurando una buena relación artista-fan tanto de forma orgánica como en términos algorítmicos.
- Trabajar en tu estrategia de marketing musical: Aunque el algoritmo de Spotify es una herramienta poderosa para promocionar tu música, como hemos visto, también es importante tener una estrategia de promoción rentable, ya sea a través de métodos gratuitos o de pago. Esto puede incluir utilizar las redes sociales y el marketing digital, como Meta Ads o Google Ads, para dirigir a la audiencia hacia tu perfil de Spotify o promocionar un nuevo lanzamiento. Aquí es importante mostrarle al algoritmo que muchos usuarios pueden querer escucharte el mismo día del lanzamiento, lo que aumentará tu relevancia y posicionamiento en las playlists algorítmicas.
- Colaborar con otros artistas: Es importante verificar el recuento de oyentes mensuales en tu perfil al menos una vez a la semana. Una forma de aumentar significativamente ese número es colaborando con artistas que tengan al menos un número similar de oyentes. De esta manera, Spotify sabrá que es probable que estés colaborando para obtener una mayor presencia en los algoritmos de recomendación.
- Utilizar la plataforma de publicidad de Spotify: Permite a los artistas crear anuncios de audio y mostrarlos a los usuarios en función de sus intereses y hábitos de escucha, lo que yo llamo “pagar para algoritmizar”. Muchos artistas han aprovechado con éxito esta oportunidad para cargar sus propios anuncios y experimentar rápidamente un ROI inesperado en términos de reproducciones. También podrías aprovechar la herramienta Discovery Mode.
Los metadatos son algo que no se puede pasar por alto y Spotify los verifica dos veces. Primero, cuando la distribuidora envía el lanzamiento. Y luego, cuando pasás por el proceso de presentación para playlists editoriales (conocido como pitching). La información que se procesa a través de los algoritmos es la siguiente:
- Título de la canción
- Título del lanzamiento
- Nombre del artista
- Colaboraciones (“featurings”)
- Compositores
- Productores
- Sello discográfico
- Fecha de lanzamiento
- Género y sub-géneros
- Cultura musical
- Estados de ánimo
- Estilo
- Idioma principal
- Instrumentos
- De estudio / en vivo
- Cover / remix / instrumental
- Ciudad de origen del artista
Cuando envíes o “pitchees” tu canción, asegurate de describir también tu estrategia de marketing musical en el cuadro de descripción. De esta manera, Spotify sabrá tu interés en posicionarte lo más alto posible y la cantidad de trabajo, tiempo y/o dinero que has invertido en ello.
Si tenés un sello discográfico, sería recomendable asegurarte siempre de que toda esa información esté disponible. De esta manera, podrás vincularte con artistas de tu propio catálogo. No olvides también de crear tus listas de reproducción personalizadas y colocarlas en tu perfil de artista.
Tanto los curadores de playlists editoriales como aquellos de nosotros que trabajamos como curadores de manera independiente, prestamos atención a aquellos artistas que se toman el tiempo de proporcionarnos información detallada sobre sus canciones. Esto nos permite comprender cuán importante es para el artista que se incluyan sus lanzamientos en nuestras listas de reproducción y construir relaciones sociales y comerciales más estrechas.
Ingresá en nuestra nueva comunidad en Skool por solo $10 dólares al mes
¿Dónde puedo ver mi actividad de manera amigable?
Hay varios proyectos que utilizan la API de Spotify para proporcionar información visualmente amigable al usuario. Algunos trabajan con información ampliada, mientras que otros van directo al grano.
Como primer ejemplo, usaré StatsForSpotify.com, un sitio web extremadamente simple donde puedo ver rápidamente mis comportamientos de escucha para pistas, artistas y géneros y comprender por qué se me han recomendado ciertas canciones en las últimas semanas. Una característica interesante es la sección de géneros musicales, donde puedo ver lo que escucho y entender mejor cómo Spotify tiende a categorizar subgéneros. En mi caso, los géneros más escuchados son House, Tech House, Funky Tech House y UK Dance. Esto me ayuda a entender que muchas canciones probablemente estén categorizadas bajo 3 de estos 4 etiquetas y posiblemente otras que se alineen con canciones que no he estado escuchando.
En cuanto a las aplicaciones móviles, prefiero usar Stats.fm, que ofrece un informe completo de actividad para aquellos que desean profundizar en sus comportamientos y hábitos en Spotify. Tiene una versión gratuita y una de pago, pero la versión gratuita es suficiente. En esta aplicación, los géneros y subgéneros que parece que escucho más son House, Disco House, Deep Groove House y Funky Tech House. Similar al ejemplo anterior, UK Dance ocupa el puesto #6 aquí. También me dice que el 87% de las canciones que he estado escuchando son “energéticas” y el 68% son “bailables”, lo cual se alinea bastante con los géneros mencionados (y da sentido al ejemplo matemático que hemos visto).
Obscurify Music me informa que he estado escuchando canciones más tristes últimamente, pero me da un ejemplo de una canción lanzada por Toolroom. ¿Cómo podría considerar la música house como algo triste? No lo sé. Por otro lado, me encantó la segmentación por décadas, que muestra lo que he estado escuchando según diferentes períodos de tiempo. Soy fan de los años 80, pero suelo escuchar esos discos en vinilo. Según estas estadísticas, mi era favorita es la de los años 2000, aunque el problema aquí es que, por ejemplo, un álbum en vivo de un grupo de rock argentino lanzado en 1985 figura como 2014 (fecha de lanzamiento de la versión remasterizada), lo cual es información parcialmente incorrecta.
Un sitio web que me ha dado mucha diversión es Pudding.cool, una inteligencia artificial que analiza los hábitos de escucha en Spotify, te conversa y te hace preguntas aleatorias, brindando un análisis único de personalidad con un tono satírico. En serio, inténtalo.

Este método de analizar nuestro comportamiento es ideal cuando subimos nuestra nueva música a través de agregadores y también cuando presentamos una canción para playlists editoriales. Los metadatos, como mencioné anteriormente, son extremadamente importantes y etiquetar nuestras canciones de la manera más precisa posible con los géneros y subgéneros nos dará una mejor oportunidad de ser recomendados al público adecuado.
Conclusiones finales
Aunque el algoritmo es complejo y sofisticado, los artistas pueden aprovecharlo creando una presencia sólida en la plataforma, fomentando la interacción con los usuarios y trabajando en su estrategia de promoción. Con el tiempo, el algoritmo de Spotify seguirá evolucionando y mejorando, brindando a los artistas aún más oportunidades para llegar a nuevos fans y expandir su alcance en la plataforma.
Además, Spotify también ha lanzado una variedad de herramientas para ayudar a los artistas a comprender mejor a su audiencia y mejorar sus estrategia. La aparición de Spotify para Artistas abrió un nuevo tipo de análisis para la música que se escucha. Los artistas podemos ver cómo están funcionando las canciones en la plataforma en tiempo real y obtener información sobre los oyentes, su ubicación, género y edad. Spotify para Artistas ofrece herramientas como Discovery Mode, Canvas, Marquee y Showcase que permiten amplificar las estrategias de marketing musical dentro de la plataforma de Spotify.
Sin embargo, es importante recordar que el algoritmo de Spotify no es el único determinante del éxito de un artista en la plataforma. La calidad de la música y la interacción con los fans son igualmente importantes para construir una carrera sostenible en la industria musical.
Véase también Cómo entender a tu audiencia en Spotify.
Referencias
J. Li, “Analysis of the Trend of Spotify”, 2022 (Research Gate)
A. Werner, “Organizing music, organizing gender: algorithmic culture and Spotify recommendations”, 2018 (Taylor & Francis Online)
N. Montecchio, P. Roy, F. Pachet, “The skipping behavior of users of music streaming services and its relation to musical structure”, 2020 (Research Gate)
Spotify AB, “Identification of taste attributes from an audio signal”, 2018 (Justia Patents)
Q. Baterna, “The Dark Side of Spotify Data Collection”, 2021 (Make Use Of)
B. Sturm, “Machine learning research that matters for music creation: A case study”, 2019 (Taylor & Francis Online)
P. Vonderau, “Spotify Teardown: Inside the Black Box of Streaming Music”, 2019 (Academia.edu)
M. Eriksson, A. Johansson, “Keep Smiling! Time, Functionality and Intimacy in Spotify’s Featured Playlists”, 2016 (Berkeley)
B. Shetty, “An In-Depth Guide to How Recommender Systems Work”, 2023 (Built In)
Wikipedia, “Netflix Prize”
J. McInerney, B. Lacker, S. Hansen, K. Higley, H. Bouchard, A. Gruson, R. Mehrotra, “Explore, Exploit, and Explain: Personalizing Explainable Recommendations with Bandits”, 2018
D. Pastukohv, “Inside Spotify’s Recommender System: A Complete Guide to Spotify Recommendation Algorithms”, 2022 (Music Tomorrow)
C. Lomboy, “How I built an Audio-Based Music Genre Predictor using Python and the Spotify Web API”, 2020 (Towards Data Science)


Está muy bueno el artículo y es bastante descriptivo en cuanto a los algoritmos que utiliza. Dado el interés que despierta a las nuevas generaciones este tipo de aplicaciones, su masividad y el uso cotidiano me pregunto si se es consciente que los algoritmos mejoran con la capacidad de hipotetizar en base a la información que le damos los Usuarios para las búsquedas.
Los algoritmos de ML necesitan ser entrenados para orientar a panoramas posibles. Aclaro esto, porque sino pareciera que el usuario es un mero consumidor y no produce al utilizar estas tecnologías.